
VDURA (previously known as Panasas) announced its V5000 All-Flash Appliance, an all-flash NVMe system designed to meet the surging demand for high-performance AI storage. Originally planned for 2026, this release has been fast-tracked to respond to the market’s interest in Generative AI (GenAI) and other data-intensive workloads. Built on the VDURA V11 data platform, the V5000 delivers GPU-saturating throughput while ensuring 24/7 data availability and durability.
At the heart of this release is F Node, a compact 1U platform running VDURA V11 software, featuring Intelligent Client-Side Erasure Coding for seamless scalability and reliability. Key specs include:
- PCIe Gen 5 and OCP slots for high-speed connectivity.
- NVIDIA CX-7 SmartNICs for ultra-low latency data transfers.
- AMD EPYC 9005 CPUs, 384GB RAM, and up to 12 U.2 128TB NVMe SSDs, packing 1.5PB per rack unit.
Seamless Scaling for AI Workloads
AI storage needs are unpredictable – scaling up often means costly overprovisioning. VDURA takes a different approach, enabling organizations to scale dynamically from a few nodes to thousands without downtime. As GPU clusters grow, V5000 storage nodes can be added on demand, ensuring performance and capacity scale in sync.
By combining all-flash and hybrid nodes, VDURA delivers a unified storage architecture that supports high throughput during training operations and cost-efficient storage for training datasets at rest.
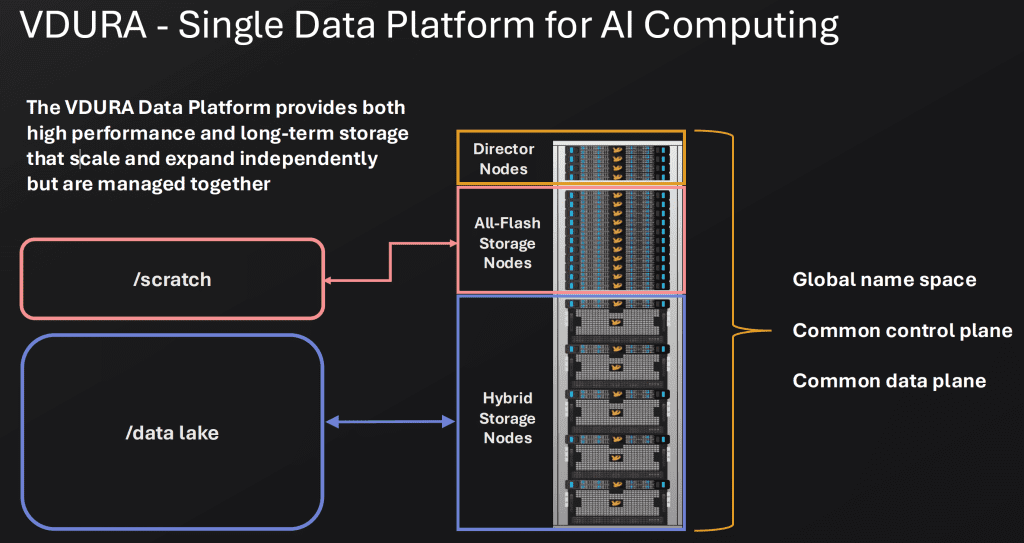
Optimized for AI Performance and Efficiency
AI workloads introduce unique storage challenges, particularly around checkpointing and sustained high-bandwidth data access. VDURA’s parallel file system (PFS) architecture is designed to eliminate these bottlenecks. Its Intelligent Client-Side Erasure Coding reduces CPU overhead, while RDMA acceleration and flash optimization ensure consistent, scalable performance. Key benefits include:
- Seamless AI Storage Expansion – Scale on demand, no overprovisioning required.
- AI Checkpoint Optimization – Eliminates write bottlenecks that slow down AI training.
- High-Density Efficiency – 1.5PB+ per RU, minimizing power, cooling, and footprint costs.
- RDMA Acceleration – GPU Direct and RDMA optimizations rolling out in 2025.
Radium, an NVIDIA Cloud Partner, is among the first to deploy the V5000 to support its large-scale AI infrastructure.
The Osmium Perspective
With the early launch of the V5000, VDURA is addressing the growing demand for high-performance, scalable AI storage. This release provides both existing customers with an upgrade path and new customers with a high-density, all-flash solution designed for AI, HPC, and other data-intensive workloads.
The V5000 delivers high-throughput AI storage today, with RDMA and GPU Direct support planned later in 2025 to further enhance performance and integration. Its global namespace, powered by VeLO technology (a key value store for small files & metadata, optimized for flash), allows seamless integration of hybrid and all-flash nodes, enabling organizations to scale storage efficiently without rearchitecting their infrastructure.
The VDURA V5000 is available now for evaluation with select customers; broader availability is planned later this year.
